Team Discussions: All About JupyterHub
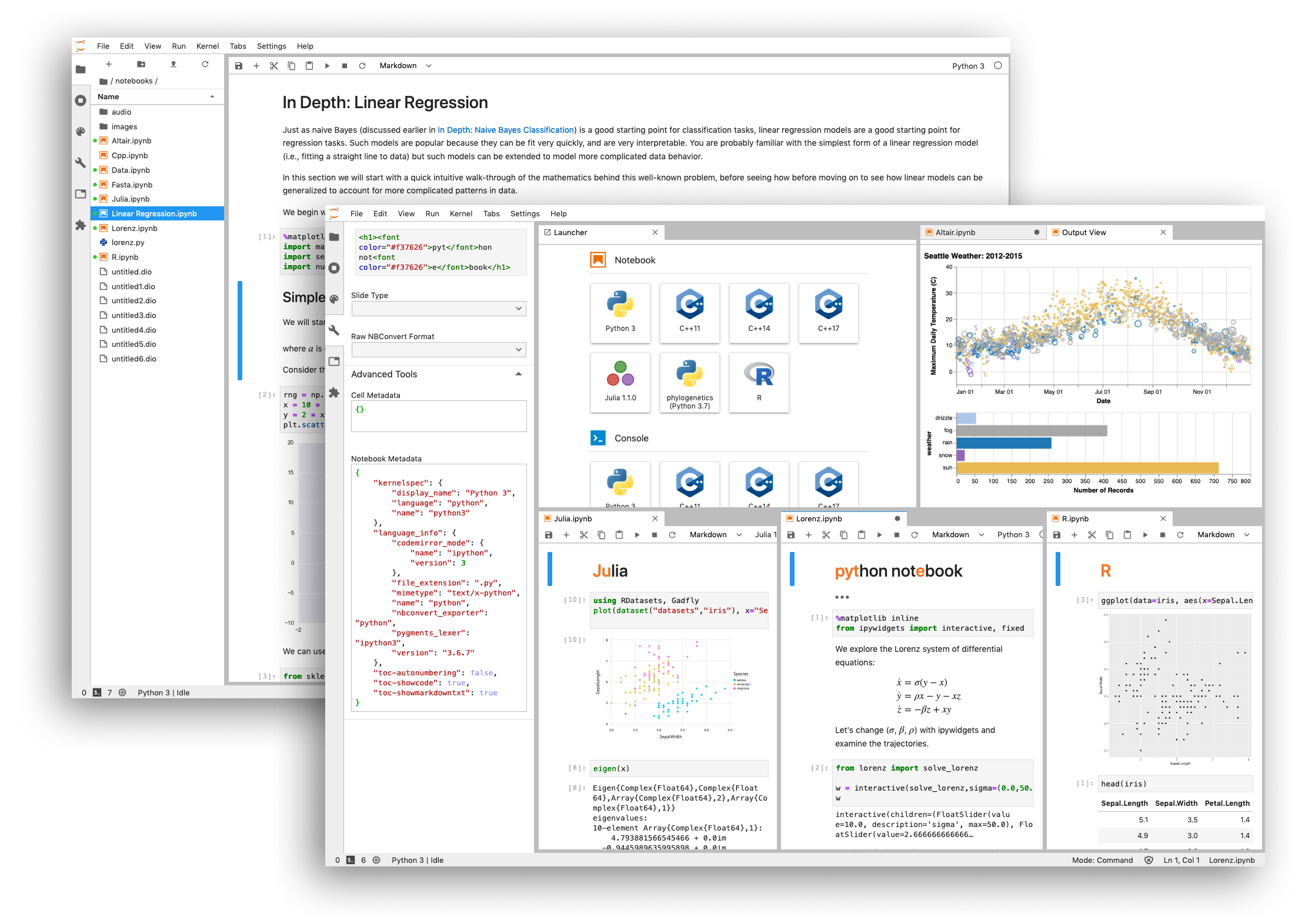 Image credit: Jupyter.org
Image credit: Jupyter.orgWe recently spoke with IronHacks.com Platform Developer Matt Harris about Jupyter, JupyterHub, and the way the team uses this technology on the platform and behind the scenes.
What is JupyterHub?
OK, so before you can understand JupyterHub, you have to know what Jupyter and iPython are. iPython is a way for you to work directly in your browser on files that are called notebooks.
iPython is the python “kernel” for Jupyter, which also has lots of other kernels available (python is the one we’re using). This allows you to many different computer programming language running in a web based environment, which typically is not possible)
So JupyterHub is a way for you to have multiple users working on a server in their own notebooks and files supporting multiple programming languages.
In general it is a server side platform that spawns iPython notebooks.
(Read more about iPython at https://ipython.org)
How did we use the JupyterHub server (IronHub) during IronHacks?
In the past our users' tasks involved building web based apps involving HTML, CSS and JavaScript code to solve problems. Recently we wanted to focus more on data science work with the platform. So, the web development framework stuff wasn’t really appropriate for doing things like modeling and analysis of big data sets.
The Jupyter platform lets participants run Python code for statistics and modeling quite easily, and then it keeps everything in a single self-contained file which greatly simplifies the submission process.
It allows users to do 100% of the work on our platform, download the file and submit their finished product back on the hack submission page. So, are there any alternatives?
Not that I’m aware of. If you want to run Python code or data science in a web browser, you’re probably going to use Jupyter.
How does it compare to what Kaggle and Google Colab offer?
Kaggle offers an integrated Python notebook environment very similar to JupyterHub called “Kaggle Kernels”. It might even be JupyterHub on the back end, but it’s integrated into their main platform.
I don’t know exactly the specifics of Google Colab but it’s also very similar. Kaggle is now owned by Google by the way. I’m not sure if it’s not the same backend as JupyterHub, but the key difference is how it’s integrated with the Google Drive Suite. With Colab, all of the file management is integrated with Google Drive.
Additionally it leverages the Google Cloud platform, so you can actually run more complex processing on Google’s GPU’s and you can connect with Google Cloud platform like services to run really complicated things as well as directly import data from Google Cloud (note: this may require some advanced setup).
The key difference with JupyterHub is that it is a stand alone system that developers or small groups can use to run on their own servers for their team or extend it to their users. JupyterHub allows complete ownership of the service and data that you can’t get if you’re using someone else’s platform (like Kaggle or Google Colab).
So how do we now use this for research, or what are the benefits right now? Basically for someone actually studying behavior in data science, how’s that actually beneficial?
JupyterHub on its own is a management system for individual users, it’s more of a server side platform, but a better question would be “How can you use notebooks for improving the workflow of research?”
Notebooks have very good use cases in some situations, and they can be less favorable in other places. For example where maybe you’re working on a package or an individual script that runs an analysis, or something that needs to be used by another program. This might happen when you’re developing some kind of modeling technique.
Where notebooks are really great is when you want to present some results in a kind of single self contained file that is shareable with someone. If you want to say, hey, here’s some writing, and here’s what I did and here’s some charts.
Notebooks are also really great for data exploration. You can use the interactive widgets that are available in iPython to explore data and better understand things about the data. Which if you’re only working from like a command line tool that wouldn’t be very appropriate or easy.
Now let’s go back like we as a team here at RCODI, what are the features of the hub we can use to do research? I’m talking about the trace data. I’m referring to that, so how will we be using this?
While it’s not completely perfect, the Jupyter does have a very good history logging system for every notebook file. For each user that comes in and does something, we’re able to understand what all the actions they took and what commands they ran. So if you’re interested in mapping a user’s thought process while solving a specific problem, you can. You can use the history data to understand exactly what they did.
We aren’t looking at every single command that’s executed, but we do extract information from those history files to create, more of maybe like a trend or big picture overview, of what the participant was working on or how much effort they put in over a specific time range.
One of things that makes the history logging ‘not completely perfect’, is (1) the history only exists for the python kernel currently and (2) there is no timestamp associated with the history.
And is that a challenge for analysis if you don’t have timestamp data?
Yes, It has been a challenge for us trying to connect activity with things that take place off of the hub. We also don’t know the exact length of time that happened between things on the hub since the history data is only sequential. There might be some way to kind of hack on the hub code to enable timestamps for every history entry, but we haven’t been able to do it so far.
This is an area for improvement in JupyterHub. We looked at different options for tracking history in python and R, but this is an issue that comes with open source software development. Each of the pieces (kernels) are built by different groups of people with different commitment levels and some of the features that we would like them to have are not in line with what the maintainers have time to do or really think is appropriate for their development time.
So what are the next steps? Or maybe is my final question in terms of how we can better use it to help in terms of the technical side of using it? Any thoughts on that?
There are updates to the platform every day, so there’s always new features that we could be leveraging. In terms of using it better as a team, though, there’s a lot we could do. We could run our own hub for the internal research team. We could create something like a data depot sharing across the team members. That’s not something we have for the hub right now because all of the participants' data would be visible across hacks and we don’t want users all having access to each other’s files, but we could do something like within our own research group.
We discussed potential audio files instead, or what are the challenges there?
A lot of what we’ve been able to do with maybe up to 40 or 50 people in the hub environment hasn’t been very computationally expensive. They mostly do regressions and computing just presence, absence, or simple modeling. These types of analysis are not as computationally difficult as something like sound analysis on very large files. Sound files tend to be very large and if we have a lot of them, we would have to be very creative in how we deploy that data to each individual user’s environment, otherwise we would quickly run out of space. For example some of the soundscape data used here at Purdue is so large that there can’t even be a copy of it. So we obviously couldn’t deploy that to all of the different individual users.
For analysis without we would, we would quickly run out of space and also the amount of processing power would be very high. Something that could take a supercomputer a very long time. We wouldn’t be able to do that very easily in everyone’s notebook without at least maybe stripping down the data and shrinking what we were trying to do.
Anything else you want to share?
I think it would be useful to think about how we could better use it internally. I think that’s something we could explore more. Right now we’re still using the Google Colab, so to speak, for collaborative work and data sharing rather than building our own internal JupyterHub. Colab is nice, but it’s not perfect for when we want to share data across users. Due to the way it loads data from Drive, it’s not really user friendly across projects. There is definitely a use case for JupyterHub in the future for improved teamwork and sharing.
Learn more about IronHacks and participate in Data Science Challenges at ironhacks.com
Did you find this page helpful? Consider sharing it 🙌
IronHacks Team
Development at IronHacks.com
Hack for innovation to solve global challenges.